Hard to believe it has been almost exactly four years since my previous duplicate finder performance comparison (2018 edition)! Life has been very busy since, so dupd has not had a release with new functionality (I did release dupd 1.7.1 last year but it only contains build and test fixes, no functionality difference from 1.7).
It’s been so long that it’s time to do another test run even though dupd has not changed, just to see how the duplicate finder performance landscape looks like in 2022.
This time I will be testing:
- dupd 1.7.1 (functionally same as 1.7 from 2018 so no real update)
- rmlint 2.9.0 (runner-up from previous test, updated version)
- jdupes 1.21.0 (third place from previous test, updated version)
- rdfind 1.4.1 (fourth place from previous test, updated version)
- fclones 0.27.3 (new one which I had not tried before)
- yadf 1.0 (new one which I had not tried before)
I’m no longer testing the following ones, as they were too slow last time: duff, fdupes, fslint.
If you know of any other promising duplicate finder please let me know!
The files
The file set has a total of 154205 files. Of these, 18677 are unique sizes and 1216 were otherwise ignored (zero-sized or not regular files). This leaves 134312 files for further processing. Of these, there are 44926 duplicates in 13828 groups (and thus, 89386 unique files). It is the exact same data set as in the 2018 performance test run.
The files are all “real” files. That is, they are all taken from my home file server instead of artificially constructed for the benchmark. There is a mix of all types of files such as source code, documents, images, videos and other misc stuff that accumulates on the file server.
Same as last time, I have the same set of files on an SSD and a HDD on the same machine, so I’ll run each program against both sets.
The cache
Same as last time, I’ll run each program and device combination with both a warm and a cold (flushed) file cache
The methodology
Will be identical to the 2018 test (as I’m using the same script to run each program). To recap:
For each tool/media (SSD and HDD) combination, the runs were done as follows:
- Clear the filesystem cache (echo 3 > /proc/sys/vm/drop_caches).
- Run the scan once, discarding the result.
- Repeat 5 times:
- For the no-cache runs, clear the cache again.
- Run and time the tool.
- Report the average of the above five runs as the result.
The command lines and individual run times are included at the bottom of this article.
Results
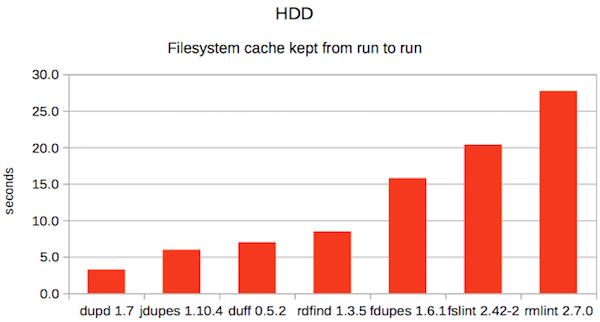
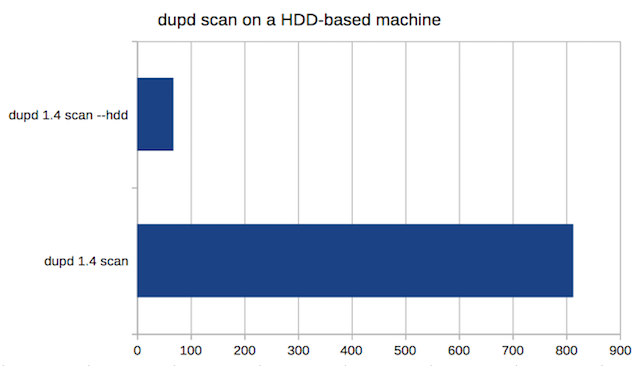
1. HDD with cache
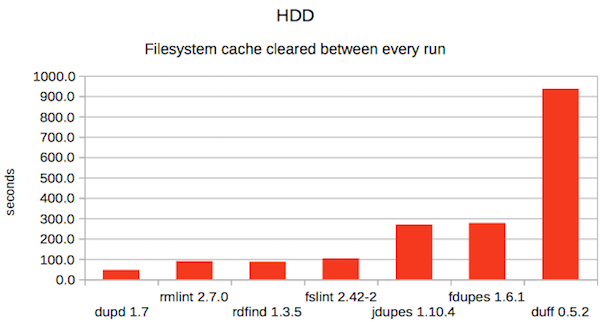
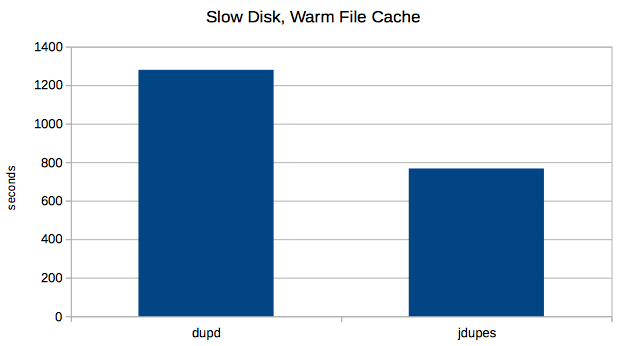
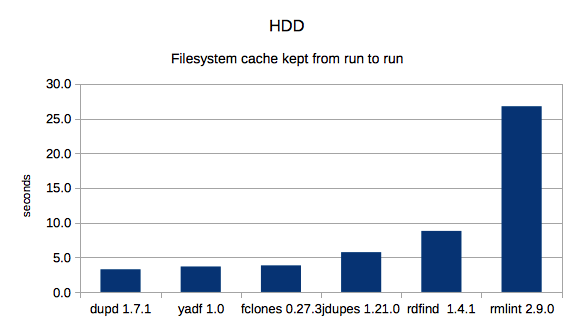 2. HDD without cache
2. HDD without cache
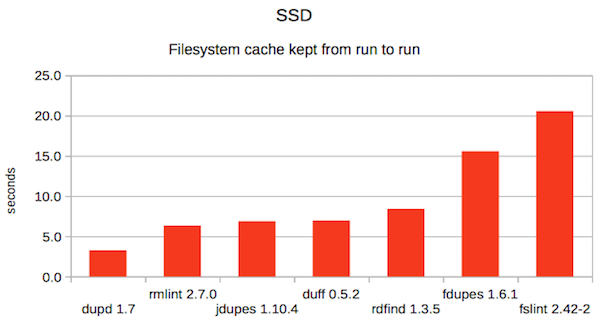
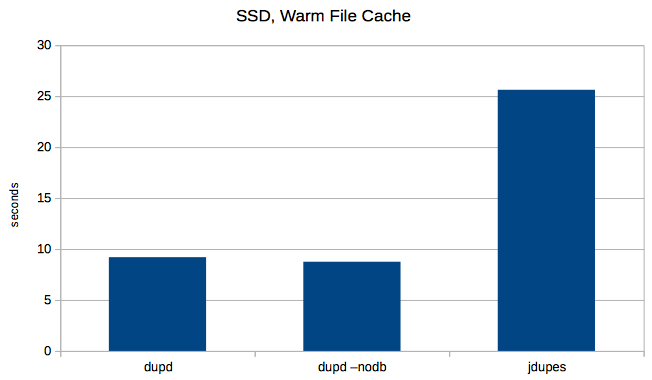
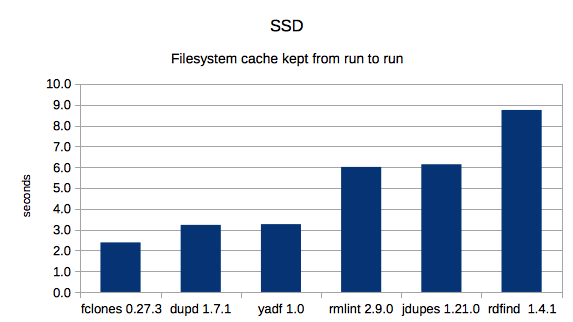
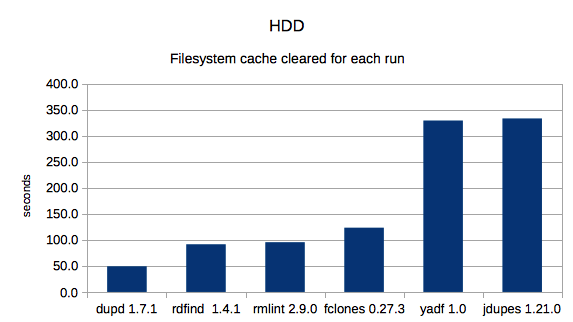 3. SSD with cache
3. SSD with cache
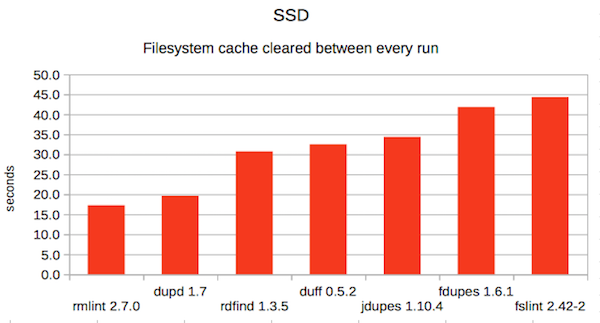
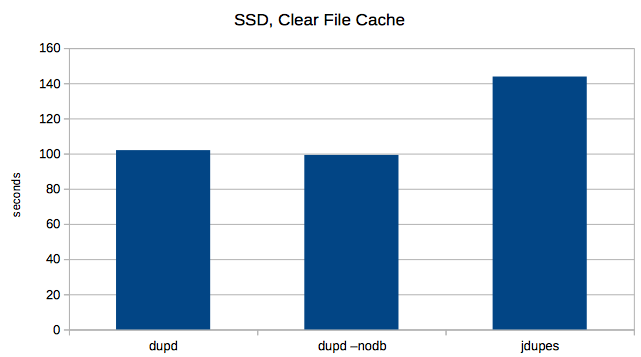
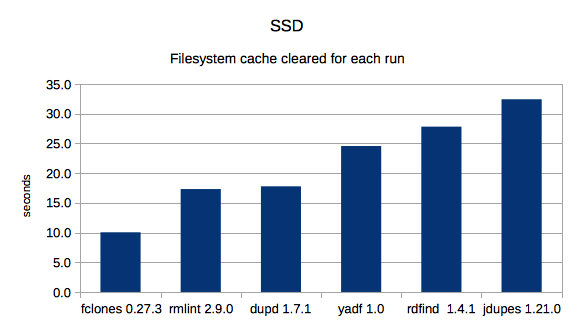
 4. SSD without cache
4. SSD without cache
Summary
As always, different tools excel in different scenarios so there isn’t any one that wins them all.
For an overall ranking, let’s average the four finishing positions like I did last time:
| Tool | aveRAGE ranking | |
|---|---|---|
| dupd | 1.8 | 1, 1, 2, 3 |
| fclones | 2.3 | 3, 4, 1, 1 |
| yadf | 3.5 | 2, 5, 3, 4 |
| rmlint | 3.8 | 6, 3, 4, 2 |
| rdfind | 4.5 | 5, 2, 6, 5 |
| jdupes | 5.3 | 4, 6, 5, 6 |
This time, dupd was fastest in both HDD scenarios and fclones was fastest in both SSD scenarios. Overall, dupd gets the best overall average rank thanks to doing slightly better than fclones in the categories each didn’t win.
The other newcomer, yadf, didn’t excel anywhere but scored consistently enough to come in third place.
In summary, some strong new competition from fclones in the duplicate finding space. I am happy to see that dupd still came in first place (although barely) even though it hasn’t really evolved in the last four years.
I do intend to release a dupd 2.0 at some point but haven’t really had any time to get it into shape. Whenever I get some time to do that, I’ll do another performance test run.
The Raw Data
-----[ yadf : CACHE KEPT : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 328.81 Running 5 times (timeout=3600): yadf -H /hdd/files Run 0 took 3.77 Run 1 took 3.66 Run 2 took 3.64 Run 3 took 3.67 Run 4 took 3.65 AVERAGE TIME: 3.678 -----[ rmlint : CACHE KEPT : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 92.61 Running 5 times (timeout=3600): rmlint -o fdupes /hdd/files Run 0 took 26.65 Run 1 took 26.81 Run 2 took 26.73 Run 3 took 26.86 Run 4 took 26.91 AVERAGE TIME: 26.792 -----[ jdupes : CACHE KEPT : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 333.15 Running 5 times (timeout=3600): jdupes -A -H -r -q /hdd/files Run 0 took 5.74 Run 1 took 5.71 Run 2 took 5.85 Run 3 took 5.71 Run 4 took 5.72 AVERAGE TIME: 5.746 -----[ dupd : CACHE KEPT : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 49.51 Running 5 times (timeout=3600): dupd scan -q -p /hdd/files Run 0 took 3.31 Run 1 took 3.29 Run 2 took 3.27 Run 3 took 3.22 Run 4 took 3.24 AVERAGE TIME: 3.266 -----[ rdfind : CACHE KEPT : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 92.94 Running 5 times (timeout=3600): rdfind -n true /hdd/files Run 0 took 8.89 Run 1 took 8.85 Run 2 took 8.78 Run 3 took 8.77 Run 4 took 8.78 AVERAGE TIME: 8.814 -----[ fclones : CACHE KEPT : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 121.67 Running 5 times (timeout=3600): fclones group /hdd/files Run 0 took 3.89 Run 1 took 3.8 Run 2 took 3.82 Run 3 took 3.82 Run 4 took 3.82 AVERAGE TIME: 3.83 -----[ yadf : CACHE CLEARED EACH RUN : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 330.77 Running 5 times (timeout=3600): yadf -H /hdd/files Run 0 took 327.95 Run 1 took 328.46 Run 2 took 329.36 Run 3 took 329.6 Run 4 took 333.01 AVERAGE TIME: 329.676 -----[ rmlint : CACHE CLEARED EACH RUN : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 107.27 Running 5 times (timeout=3600): rmlint -o fdupes /hdd/files Run 0 took 101.8 Run 1 took 99.69 Run 2 took 97.9 Run 3 took 96.67 Run 4 took 82.37 AVERAGE TIME: 95.686 -----[ jdupes : CACHE CLEARED EACH RUN : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 333.89 Running 5 times (timeout=3600): jdupes -A -H -r -q /hdd/files Run 0 took 333.53 Run 1 took 333.49 Run 2 took 335.22 Run 3 took 332.42 Run 4 took 333.83 AVERAGE TIME: 333.698 -----[ dupd : CACHE CLEARED EACH RUN : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 49.42 Running 5 times (timeout=3600): dupd scan -q -p /hdd/files Run 0 took 49.4 Run 1 took 49.26 Run 2 took 49.29 Run 3 took 49.11 Run 4 took 49.27 AVERAGE TIME: 49.266 -----[ rdfind : CACHE CLEARED EACH RUN : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 92.08 Running 5 times (timeout=3600): rdfind -n true /hdd/files Run 0 took 91.72 Run 1 took 91.66 Run 2 took 91.6 Run 3 took 91.6 Run 4 took 91.75 AVERAGE TIME: 91.666 -----[ fclones : CACHE CLEARED EACH RUN : /hdd/files]------ Running one untimed scan first... Result/time from untimed run: 121.85 Running 5 times (timeout=3600): fclones group /hdd/files Run 0 took 125.28 Run 1 took 126.19 Run 2 took 123.47 Run 3 took 121.69 Run 4 took 121.29 AVERAGE TIME: 123.584 -----[ yadf : CACHE KEPT : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 24.14 Running 5 times (timeout=3600): yadf -H /ssd/files Run 0 took 3.35 Run 1 took 3.26 Run 2 took 3.22 Run 3 took 3.23 Run 4 took 3.24 AVERAGE TIME: 3.26 -----[ rmlint : CACHE KEPT : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 17.43 Running 5 times (timeout=3600): rmlint -o fdupes /ssd/files Run 0 took 6.23 Run 1 took 6.17 Run 2 took 5.8 Run 3 took 5.64 Run 4 took 6.21 AVERAGE TIME: 6.01 -----[ jdupes : CACHE KEPT : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 33.1 Running 5 times (timeout=3600): jdupes -A -H -r -q /ssd/files Run 0 took 6.17 Run 1 took 6.09 Run 2 took 6.14 Run 3 took 6.17 Run 4 took 6.12 AVERAGE TIME: 6.138 -----[ dupd : CACHE KEPT : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 17.93 Running 5 times (timeout=3600): dupd scan -q -p /ssd/files Run 0 took 3.27 Run 1 took 3.18 Run 2 took 3.25 Run 3 took 3.29 Run 4 took 3.13 AVERAGE TIME: 3.224 -----[ rdfind : CACHE KEPT : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 28.14 Running 5 times (timeout=3600): rdfind -n true /ssd/files Run 0 took 8.76 Run 1 took 8.75 Run 2 took 8.73 Run 3 took 8.71 Run 4 took 8.8 AVERAGE TIME: 8.75 -----[ fclones : CACHE KEPT : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 10.1 Running 5 times (timeout=3600): fclones group /ssd/files Run 0 took 2.42 Run 1 took 2.39 Run 2 took 2.36 Run 3 took 2.32 Run 4 took 2.42 AVERAGE TIME: 2.382 -----[ yadf : CACHE CLEARED EACH RUN : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 24.65 Running 5 times (timeout=3600): yadf -H /ssd/files Run 0 took 24.65 Run 1 took 24.7 Run 2 took 24.44 Run 3 took 24.48 Run 4 took 24.53 AVERAGE TIME: 24.56 -----[ rmlint : CACHE CLEARED EACH RUN : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 17.29 Running 5 times (timeout=3600): rmlint -o fdupes /ssd/files Run 0 took 17.31 Run 1 took 17.36 Run 2 took 17.33 Run 3 took 17.3 Run 4 took 17.28 AVERAGE TIME: 17.316 -----[ jdupes : CACHE CLEARED EACH RUN : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 32.4 Running 5 times (timeout=3600): jdupes -A -H -r -q /ssd/files Run 0 took 32.51 Run 1 took 32.4 Run 2 took 32.28 Run 3 took 32.47 Run 4 took 32.48 AVERAGE TIME: 32.428 -----[ dupd : CACHE CLEARED EACH RUN : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 17.82 Running 5 times (timeout=3600): dupd scan -q -p /ssd/files Run 0 took 17.73 Run 1 took 17.78 Run 2 took 17.83 Run 3 took 17.79 Run 4 took 17.74 AVERAGE TIME: 17.774 -----[ rdfind : CACHE CLEARED EACH RUN : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 27.83 Running 5 times (timeout=3600): rdfind -n true /ssd/files Run 0 took 27.77 Run 1 took 27.78 Run 2 took 27.78 Run 3 took 27.99 Run 4 took 27.79 AVERAGE TIME: 27.822 -----[ fclones : CACHE CLEARED EACH RUN : /ssd/files]------ Running one untimed scan first... Result/time from untimed run: 10.01 Running 5 times (timeout=3600): fclones group /ssd/files Run 0 took 10.06 Run 1 took 10.01 Run 2 took 10.01 Run 3 took 10.04 Run 4 took 10.06 AVERAGE TIME: 10.036