Just over two years ago I tested my dupd against a couple other duplicate detection tools.
Recently I’ve been doing some duplicate cleanup again and while at it I added a few features to dupd and called it version 1.1. So this is as good time as any to revisit the previous numbers.
I tested a small subset of my file server data using six duplicate detection tools:
Results
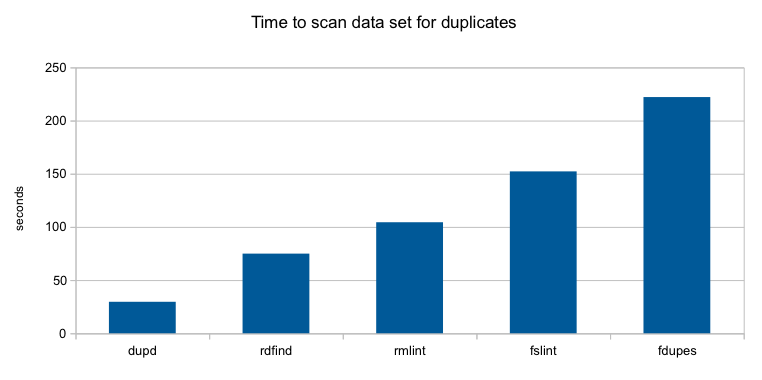
The graph shows the time (in seconds) it took each utility to scan and identify all duplicates in my sample set. I’m happy to see dupd took less than half the time of the next fastest option (rdfind) and just over seven times faster than fdupes.
Details
The Data
The sample set is 18GB in size and has 392,378 files. There are a total of 117,261 duplicates.
The Machine
I ran this on my small home server, which has an Intel Atom CPU S1260 @ 2.00GHz (4 cores), 8GB RAM, Intel 520 series SSD.
The Runs
For each tool, first I ran it once and ignored the time, just to populate file caches. Then I ran it five times in a row. Discarding the fastest and slowest time, I averaged the remaining three runs to come up with the time shown in the graph above. For most of the tools, the scan times were very consistent from run to run.
dupd
dupd scan --path $HOME/data -q 13.31s user 15.94s system 99% cpu 29.533 total
dupd scan --path $HOME/data -q 13.17s user 16.09s system 99% cpu 29.539 total
dupd scan --path $HOME/data -q 13.17s user 16.13s system 99% cpu 29.572 total
dupd scan --path $HOME/data -q 13.28s user 16.04s system 99% cpu 29.604 total
dupd scan --path $HOME/data -q 13.59s user 15.74s system 99% cpu 29.605 total
rdfind
rdfind -dryrun true $HOME/data 49.28s user 24.98s system 99% cpu 1:14.75 total
rdfind -dryrun true $HOME/data 49.08s user 25.29s system 99% cpu 1:14.87 total
rdfind -dryrun true $HOME/data 48.93s user 25.52s system 99% cpu 1:14.92 total
rdfind -dryrun true $HOME/data 48.92s user 25.53s system 99% cpu 1:14.95 total
rdfind -dryrun true $HOME/data 49.52s user 25.09s system 99% cpu 1:15.11 total
rmlint
./rmlint -T duplicates $HOME/data 63.53s user 52.55s system 113% cpu 1:42.69 total
./rmlint -T duplicates $HOME/data 64.67s user 52.46s system 113% cpu 1:43.43 total
./rmlint -T duplicates $HOME/data 64.01s user 53.14s system 113% cpu 1:43.63 total
./rmlint -T duplicates $HOME/data 66.47s user 54.32s system 113% cpu 1:46.13 total
./rmlint -T duplicates $HOME/data 67.20s user 56.00s system 113% cpu 1:48.55 total
fslint
./findup $HOME/data 129.46s user 40.77s system 111% cpu 2:32.05 total
./findup $HOME/data 129.75s user 40.53s system 111% cpu 2:32.10 total
./findup $HOME/data 129.58s user 40.82s system 111% cpu 2:32.28 total
./findup $HOME/data 129.89s user 40.80s system 112% cpu 2:32.30 total
./findup $HOME/data 130.47s user 40.34s system 112% cpu 2:32.36 total
fdupes
fdupes -q -r $HOME/data 43.16s user 170.29s system 96% cpu 3:41.87 total
fdupes -q -r $HOME/data 43.39s user 170.24s system 96% cpu 3:42.07 total
fdupes -q -r $HOME/data 42.88s user 170.87s system 96% cpu 3:42.13 total
fdupes -q -r $HOME/data 42.73s user 171.24s system 96% cpu 3:42.23 total
fdupes -q -r $HOME/data 43.64s user 170.83s system 96% cpu 3:42.86 total
fastdup
I was unable to get any times from fastdup as it errors out with “Too many open files”.

