
For most of its development, my duplicate detection utility dupd has been optimized for SSDs only. This wasn’t an intentional choice per se, just a side effect of the fact that the various machines I tend to test and develop on are all SSD based.
The 1.4 release introduces support for a new scan mode which works better on hard disk drives (HDDs). While this mode does have additional overhead (both CPU and RAM) compared to the default mode (which makes it generally slower if the data is on a SSD) it more than makes up for it by reducing the time spent waiting for I/O if the file data is scattered on spinning rust.
Here are some runs from a HDD-based machine I have. The file set consists of general data of all kinds from a subset of my home directory. There are 148,933 files with 44,339 duplicates.
The timings are the average of 5 runs, with the filesystem cache cleared (echo 3 > /proc/sys/vm/drop_caches) before each run (this is highly artificial, of course, as you’d never ever do that in real life, but interesting for testing a worst-case scenario).
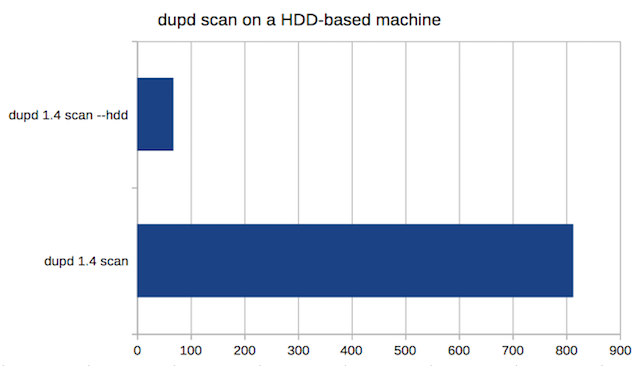 Here the –hdd mode is almost 12x faster (68 seconds vs. 813 seconds)!
Here the –hdd mode is almost 12x faster (68 seconds vs. 813 seconds)!
It is important to note that if the file data being scanned is in the filesystem cache then you are better off using the default mode even if the underlying files are stored on a HDD. If you are cleaning duplicates “the dupd way” and the machine has enough RAM then it is more likely than not that most or all of the data will be in the cache in all runs except the first one.
My rule of thumb recommendation on a HDD-based machine is to always run the first scan using the –hdd mode and then try subsequent scans both with and without the –hdd mode to see which works best on your hardware and with that particular data set. As with all things performance, YMMV!