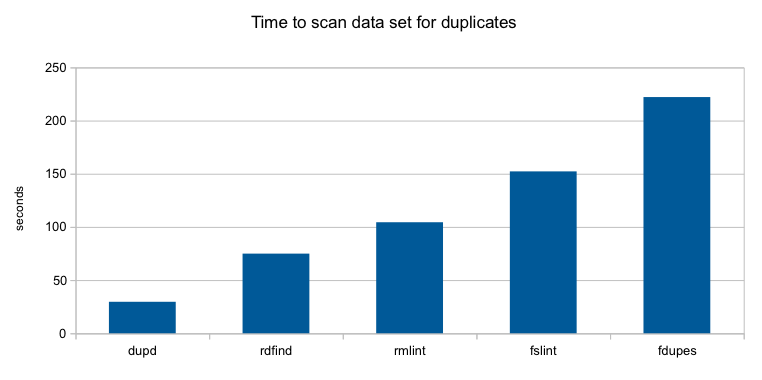
Performance Improvements in dupd 1.2
Recently I’ve done a few performance improvements to dupd, motivated by one particular edge case file set I was working with a while back. That file set had very large numbers (over 100K) of files of the same size (these were log files from a production system where the content was always different but due to the structure of the files they tended to have the same size). This was a worst case scenario for dupd given the way it grouped files of the same size as potential duplicates. With the latest changes (in dupd 1.2) this scenario is dramatically faster (scan time reduced from about an hour to about five minutes – see below).
In more common scenarios these improvements don’t make a big difference but there is still some small benefit. Memory consumption is also reduced in dupd 1.2 (there is more room to reduce memory consumption that I might play with if I have time some day).
In a nutshell, dupd 1.2 should be either no slower, slightly faster or in some edge cases dramatically faster than dupd 1.1.
The edge case: lots of files of the same size
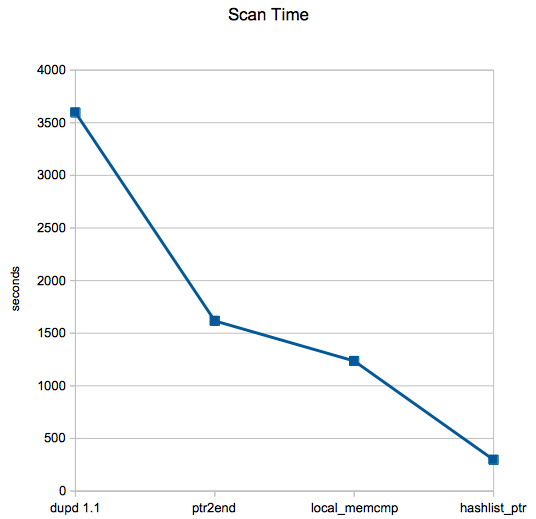 With dupd 1.1 scan time was 59m57s which is what motivated me to improve it for that file set. Now with dupd 1.2, scan time for the same file set is only 4m57s! Mission accomplished.
With dupd 1.1 scan time was 59m57s which is what motivated me to improve it for that file set. Now with dupd 1.2, scan time for the same file set is only 4m57s! Mission accomplished.
The three main changes were:
- ptr2end (Reduced time from 59m57s to 26m57s) – Simply store a pointer to the end of the size list instead of walking it. Normally the size lists are tiny, on average I see well under 10 elements. But when it grew to over 100K elements this made a huge difference.
- local_memcmp (Reduced time from 26m57s to 20m36s) – Instead of using memcmp(3) always, use a local implementation when the buffers being compared are small. This made a surprising amount of difference.
- hashlist_ptr (Reduced time from 20m36s to 4m57s) – As dupd processes file sets from the sizelist to the hashlists, it was copying the paths. Now, just copy pointers. This skips a lot of unnecessary strcpy(3)ing as well as reduces memory consumption.
Normal case: smaller set of files with no odd size distributions
That said, do these changes translate to any benefit on more “normal” file sets? Nowhere near as dramatically, but it’s still faster and uses less memory so that’s all good.
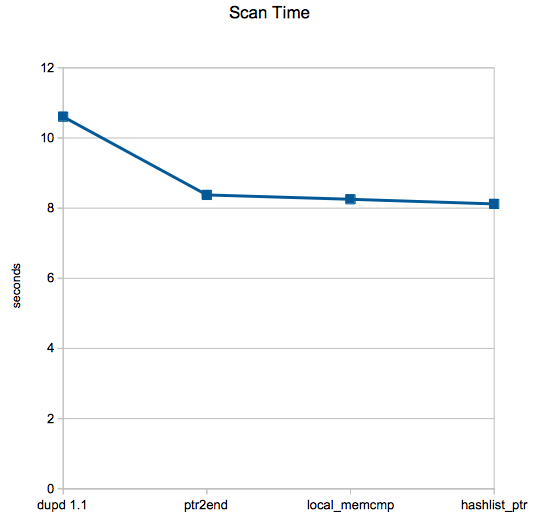 These scans are from my $HOME dir on one machine, scan time reduced from 10.6s (average of 5 runs) to 8.1s, an improvement of about 23%, not bad at all.
These scans are from my $HOME dir on one machine, scan time reduced from 10.6s (average of 5 runs) to 8.1s, an improvement of about 23%, not bad at all.
No change: spinning rust
All the numbers above are from machines with SSDs. I also tested on a couple machines with traditional hard drives and there was zero change in performance. No graph, it’s just a straight line ;-)
With normal hard drives, the file I/O time so completely dominates run time that there is no difference from any dupd improvements.
(I suspect the edge case file set would have seen improvement even on spinning rust, but I didn’t have the chance to test that scenario.)